###
# scraping international ikea websites
# 230426
###
# set path to wd ----
wdir <- getwd()
dir.create(file.path(wdir, "temp"), showWarnings = FALSE)
dir.create(file.path(wdir, "output"), showWarnings = FALSE)
setwd(wdir)
# libraries ----
pacman::p_load(rvest)
pacman::p_load(stringr)
pacman::p_load(magrittr)
pacman::p_load(data.table)
pacman::p_load(jsonlite)
pacman::p_load(tidyr)
pacman::p_load(countrycode)
pacman::p_load(ggplot2)
pacman::p_load(ggrepel)
# structure of ikea links ----
# https://www.ikea.com/de/de/p/billy-buecherregal-weiss-00263850/
# https://www.ikea.com/fr/fr/p/billy-bibliotheque-blanc-00263850/
# https://www.ikea.com/ca/en/p/billy-bookcase-white-00263850/
# https://www.ikea.com/de/de/search/products/?q=00263850
# https://www.ikea.com/ca/en/search/products/?q=00263850
# https://www.ikea.com/ca/fr/search/products/?q=00263850
# https://www.ikea.com/dk/da/search/products/?q=00263850
# custom functions ----
possibly_fromJSON = purrr::possibly(fromJSON, otherwise = NA)
possibly_html_element = purrr::possibly(html_element, otherwise=NA)
# download regions ----
regions = readLines("https://www.ikea.com/global/en/shared-data/regions.js") #read the content of the page into a vector of character strings
regions = str_remove(regions, "window\\['regions\\-10bpdvv'\\] \\= ")
regions = fromJSON(regions)
regions = regions %>% unnest(cols = "localizedSites")
setDT(regions)
regions = regions[, .(code, isoCode3, language, languageCode, url)]
# subset to the "easy" ones (rest for practice at home) ----
regions = regions[!isoCode3 %in% c("THA", "GRC", "ISL",
"TUR", "CYP", "NZL",
"CHL", "SGP", "BGR", "COL")]
regions = regions[!(isoCode3 %in% c("RUS") | isoCode3 %in% "UKR") & languageCode!="RU"]
# iterate over localized sites ----
for (i in 1:nrow(regions)) {
cat(i, "-", regions[i]$url, "\n")
# set country, language and file path
country = regions[i]$code %>% str_to_lower()
language = regions[i]$languageCode %>% str_to_lower()
file_path = str_c("temp/", country, "-", language, ".html")
# download html if necessary, then read
if (!file.exists(file_path)) {
download.file(str_c(regions[i]$url, "search/products/?q=00263850"), destfile = file_path)
}
page_search = read_html(file_path)
# extract html element with price and currency info
page_element = page_search %>%
possibly_html_element("#art_00263850 > div > div.card-body > div > div.itemPriceBox > div > p > span")
if (!is.na(page_element)) {
page_price = page_element %>% html_attr("data-price") %>% as.numeric()
page_currency = page_element %>% html_children() %>% html_text()
}
# in many cases we need to fetch the information from a json (that is then rendered locally if viewed in browser)
page_json = possibly_fromJSON(str_c("https://sik.search.blue.cdtapps.com/", country, "/", language, "/", "search-result-page?max-num-filters=8&q=00263850"))
if (!is.na(page_json[1])) {
# subset to price data.frame
page_json = page_json$searchResultPage$products$main$items$product$salesPrice
# in some countries billies have a different product number, so we just search for "billy" and pick first entry. probably error-prone
if (length(page_json) == 0) {
page_json = possibly_fromJSON(str_c("https://sik.search.blue.cdtapps.com/", country, "/", language, "/", "search-result-page?max-num-filters=1&q=billy"))
page_json = page_json$searchResultPage$products$main$items$product$salesPrice[1,]
}
# extract price
page_price = page_json$numeral %>%
str_remove_all(" ") %>%
as.numeric()
# extract currency from prefix or suffix
page_currency = page_json$currencyCode %>% str_trim()
}
# save price and currency to regions data.frame
cat("price: ", page_price, "- currency: ", page_currency, "\n")
regions[i, price := page_price]
regions[i, currency := page_currency]
}
# get exchange rates ----
data_xr = read_html("https://www.ecb.europa.eu/stats/policy_and_exchange_rates/euro_reference_exchange_rates/html/index.en.html")
data_xr = data_xr %>%
html_node("#main-wrapper > main > div.jumbo-box > div.lower > div > div > table") %>%
html_table()
setDT(data_xr)
# first two digits of currency code are equal to iso3 codes, good for merging
data_xr = data_xr[, .(currency=Currency, spot = Spot)]
# Recode suffix into currency code
regions[currency == "$", currency := "USD"]
regions[currency == "RD$", currency := "DOP"]
# merge data ----
data = merge(regions,
data_xr,
by = "currency",
all.x = T)
# within euro exchange rate is 1
data[currency == "EUR", spot := 1]
# compute relative prices to USD
data[, price := as.numeric(price)]
data[, price_rel := price / data[url == "https://www.ikea.com/de/de/", price]]
# plots ----
## scatter plot xr vs price ----
plot_data = data[!is.na(price_rel) & !is.na(spot), .(code, price_rel, spot)] %>% unique()
plot_data[, country := countrycode(code, "iso2c", "country.name")]
plot_data[, ratio := price_rel / spot]
plot = ggplot(plot_data) +
theme_minimal() +
geom_point(aes(x = price_rel, y = spot, color = ratio)) +
geom_text_repel(aes(x = price_rel, y = spot, label = country)) +
geom_abline(slope = 1, intercept = 0) +
scale_color_viridis_c() +
scale_x_log10("Relative price") +
scale_y_log10("Exchange rate")
ggsave(plot,
filename = str_c(wdir, "output/relative_billy_prices.png"),
width = 20,
height = 20,
units = "cm")
## histogram ----
plot = ggplot(plot_data) +
theme_minimal() +
geom_bar(aes(x = reorder(country, ratio), y = ratio, fill = ratio),
stat = "identity", position = "dodge") +
scale_fill_viridis_c() +
xlab("Country") +
scale_y_continuous("Ratio") +
theme(legend.title = element_blank(),
axis.text.x = element_text(angle = 45, hjust = 1))
ggsave(plot,
filename = str_c(wdir, "output/ratio_prices.png"),
width = 20,
height = 20,
units = "cm")03 — Web scraping & APIs
I can haz all the data.

Slack channel: #03-web-scraping-api
This week is about data that is all around us online, but not easily accessible through csv files or similar. Instead, while it is visible in plain side, we sometimes need to scrape information from websites.
Lecture slides
Morning session slides
Code
Here’s the code we wrote during the afternoon session:
We get these two wonderful plot:
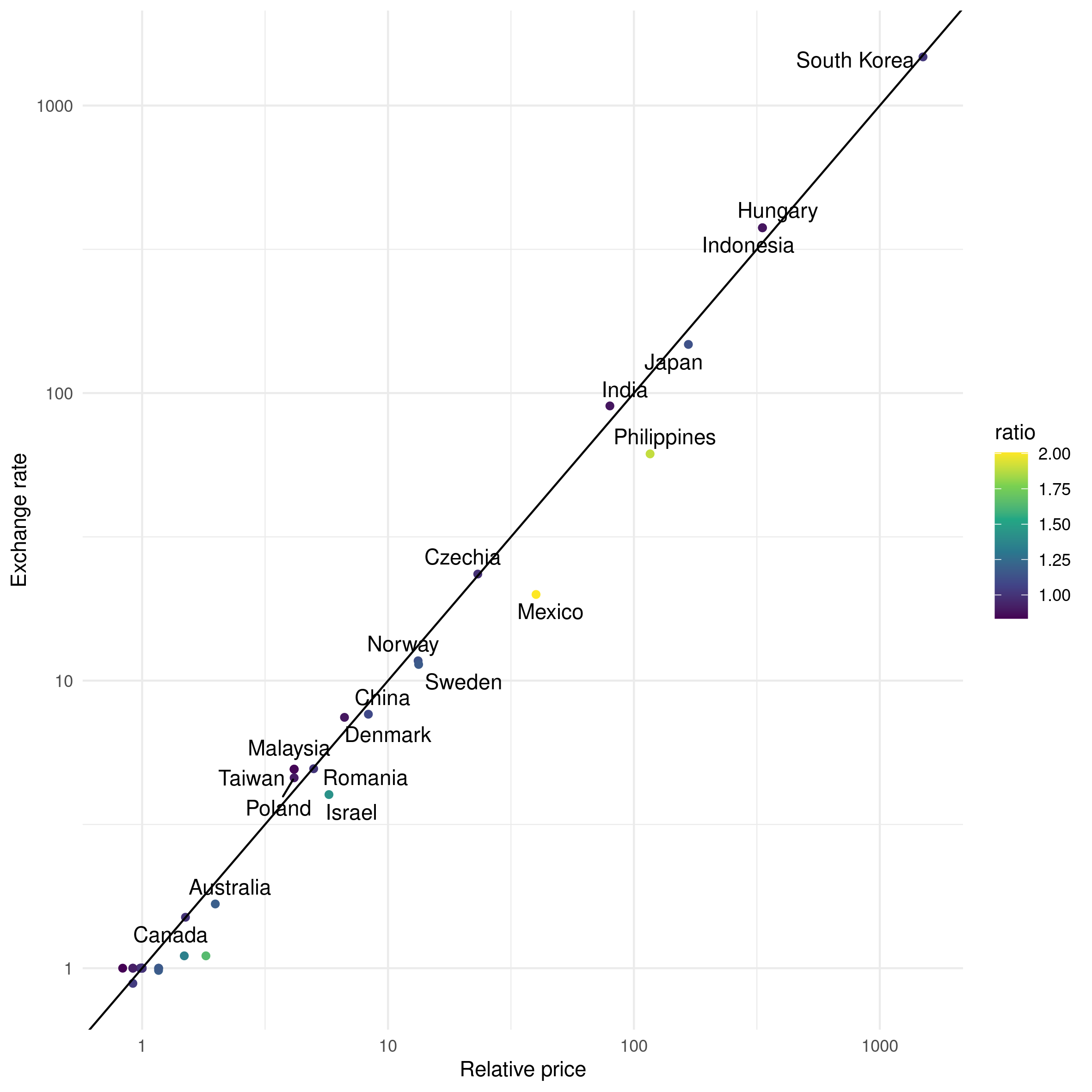
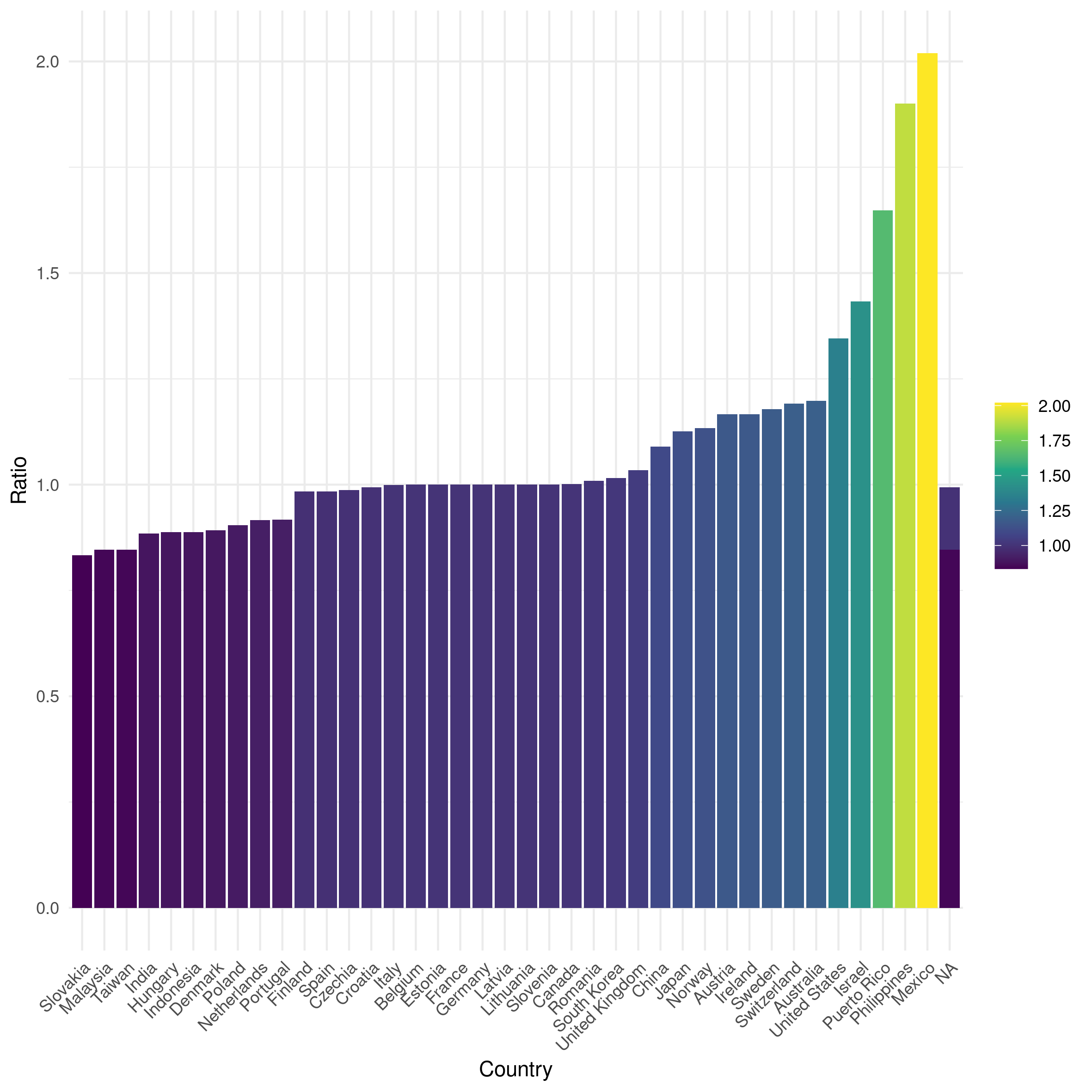
Note that we dropped some countries because of some missing data for the exchange rates, but for now: ¯_(ツ)_/¯
Further recommended resources
the Billy index was (is?) indeed a thing a while ago, here’s Der Spiegel reporting about it: The Billy Instead Of The Big Macs
as usual, Grant McDermott has superb extra resources on webscraping: https://raw.githack.com/uo-ec607/lectures/master/06-web-css/06-web-css.html and https://raw.githack.com/uo-ec607/lectures/master/07-web-apis/07-web-apis.html
we used
rvestfor scraping, if you’re using Python as an alternative, you should definitely look into Beautiful Soupand finally the link to the Billion Prices Project